
| 마이크로서비스 아키텍처의 등장

마이크로서비스 아키텍처가 언제 시작되었다고 할지는 관점에 따라 다를 수 있지만, 2014년 3월에 마틴 파울러와 샘 뉴먼이 발표한 마이크로서비스에 관한 글이 이 아키텍처의 확산에 큰 영향을 미친 것은 분명합니다. 그리고 사실, 이 글에서 제시된 마이크로서비스 아키텍처 개념은 기존 소프트웨어 개발에서 발생하는 문제들을 해결하기 위해 많은 프로젝트 현장에서 시도되고 있던 다양한 방법들을 정리한 것이기 때문에, 많은 아키텍트들과 개발자들에게 이 개념이 받아들이기 어렵다거나 뜬구름 같은 느낌으로 다가오지는 않았습니다.
대부분이 ‘마음만 먹으면 가능한’ 것들이었으니까요. 특히 당시에는 넷플릭스 OSS 스택이 출시된 상태였고, 퍼블릭 클라우드 환경의 활용도 활발히 논의되던 시기였기에 기술적으로도 큰 제약이 없었습니다. 게다가 모바일 애플리케이션 시장이 폭발적으로 성장하면서 새로운 시스템 구축에 대한 필요와 예산, 인력도 충분했던 상황이었죠. 덕분에 국내의 보수적인 소프트웨어 개발 현장에서도 마이크로서비스 아키텍처는 비교적 빠르게 확산되고 대부분 성공적으로 자리 잡을 수 있었습니다.
문제는 마이크로서비스 아키텍처의 확산이 지나치게 빠르고 성공적으로 이루어졌다는 점입니다. 일반적으로 마이크로서비스 아키텍처의 부작용이라 하면, 메모리와 CPU 수준에서 처리할 수 있는 작업이 네트워크 레벨로 옮겨지면서 발생하는 성능 문제, 조직 구조와 맞지 않는 서비스 경계로 인해 발생하는 끝없는 조직 개편과 리팩토링, 자동화되지 못한 빌드와 배포 파이프라인으로 인해 점점 커지는 배포 작업, 조직 간 커뮤니케이션 부재로 인한 오해와 오류 등이 떠오릅니다. 현재는 대부분 이러한 부작용을 방지하기 위해 마이크로서비스를 도입하기 전에 신중한 준비와 고려가 필요하다는 점을 알고 있지만, 막 마이크로서비스가 유행하기 시작했던 당시에는 ‘우리도 마이크로서비스를 도입했다’라는 선언의 유혹을 이기지 못한 많은 프로젝트 현장이 충분한 준비와 고려없이 마이크로서비스 아키텍처라는 간판을 내걸기 시작했습니다.
그 결과, 마이크로서비스 아키텍처는 현장에 지나치게 빠르게 퍼져 나갔고, 부작용에 대한 검증이 이루어지기도 전에 ‘성공’이라는 평가가 내려졌습니다. 누군가는 성공의 보상을 받고 떠났지만, 남은 사람들은 ‘성공한 프로젝트’를 이어받아 부작용을 감내하기 시작했습니다. 그리고 그 과정에서 마이크로서비스 아키텍처에 상처받는 개발자들이 하나둘 등장하게 되죠.
| 마이크로서비스 아키텍처는 왜 급하게 확산되었을까?
사실, 급하게 확산되는 상황은 마이크로서비스 아키텍처에서만 유별나게 나타나는 것은 아닙니다. 특히 연간 목표나 KPI를 위주로 개발 목표가 정해지는 기관이나 회사에서 어떤 새로운 기술 트렌드가 확산될 때 이 기술의 ‘적용’이 목표가 되는 경우가 많은 것이지요. 모바일 애플리케이션, 챗봇, 머신러닝, 클라우드, LLM, 마이크로서비스 아키텍처는 모두 각기 그 기술이 지향하는 목표와 풀고자 하는 문제가 분명하게 있는데. 현장에서는 그 기술이 왜 트렌드가 되었는지, 어떤 문제를 해결하고자 하는지, 무엇을 만들고자 하는지에 관심을 가지지 않고 ‘우리도 이거 적용했어요’라는 보고를 올리기 위한 프로젝트를 발주하고 있는 것입니다. 이러한 이유로 모바일 애플리케이션의 경우 앱 스토어에 등록만 하면 성공이고, 챗봇은 고객센터 전화번호만 알려줘도 성공이 되는, 프로젝트가 반드시 성공할 수밖에 없는 상황들이 만들어집니다.
마이크로서비스 아키텍처의 경우도 마찬가지로, 프로젝트의 성공과 실패를 판정하는 사람들이 이 서비스들이 제대로 분리되었는지, 지속적으로 배포 가능한 환경을 구축했는지, 변경에는 유연하게 대응할 수 있는지 등에 대한 판단을 할 수 있을리가 없으니 대부분의 마이크로서비스 전환 프로젝트는 프리패스로 성공할 수밖에 없었던 것이죠. 물론 그 많은 프로젝트들이 다 엉망이었다거나 하는 척만 했다는 것은 아닙니다. 대부분은 각자가 이해한 방식대로 마이크로서비스 아키텍처를 구현했죠. 하지만 그 목표가 ‘마이크로서비스 아키텍처의 적용’이었던 많은 프로젝트들은 마이크로서비스를 적용해서 얻고자 했던 가치가 무엇인지 모르는 상태로 대부분 어정쩡하게 성공했습니다.
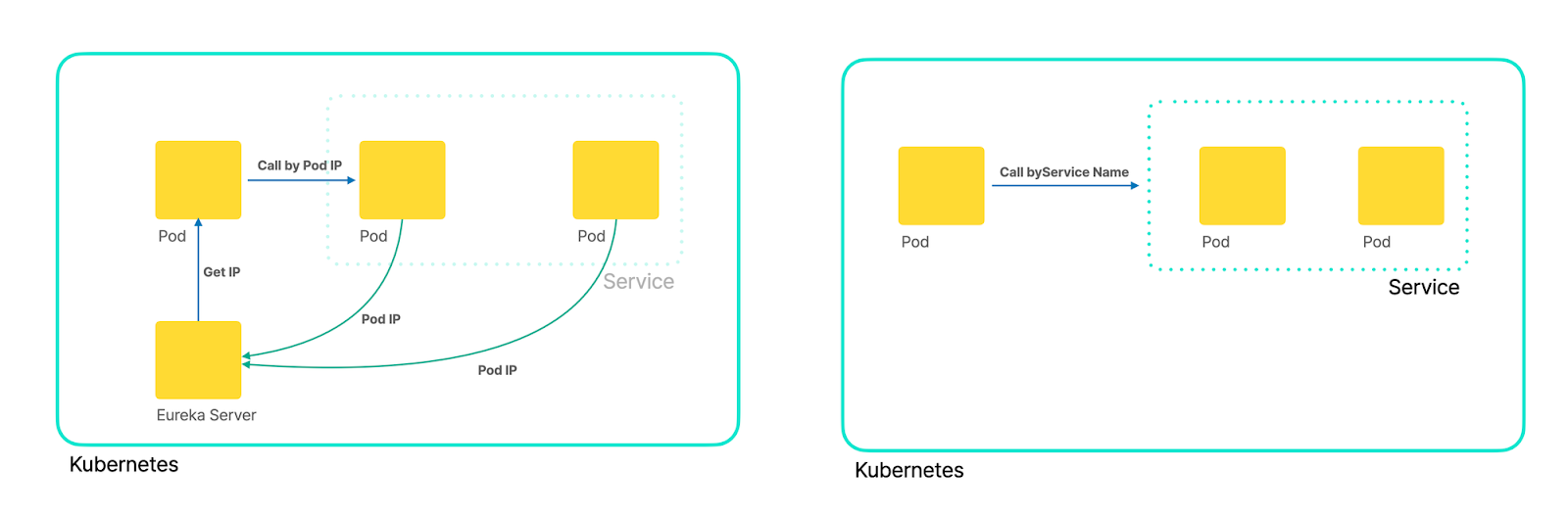
이 상황들 자체는 조금 답답할 수는 있어도 아주 큰 문제라고 보기는 어렵지만, 문제는 여기서 등장합니다. 어느 순간부터 마이크로서비스 아키텍처가 목표가 아닌 수단이 되기 시작했고, 어정쩡한 성공의 기억은 미화되어 그냥 성공의 기억으로 남게 되었습니다. 그 결과, 새로운 프로젝트를 마이크로서비스 아키텍처로 만드는 것이 당연해지게 되어 서비스를 억지로라도 나눠야되는 상황들이 발생하기 시작했고, 쿠버네티스 (Kuberentes) 환경에서 유레카(Eureka)를 띄우는 것과 같은 망측한 결과물이 나타나기 시작했습니다. 2016년쯤에 완성된 마이크로서비스 아키텍처는 넷플릭스 스택이나 스프링 클라우드 스택을 사용하는 것이 당연했고, 이 스택의 적용이 성공했으니 퍼블릭 클라우드와 쿠버네티스를 기반으로 하는 2018년이나 2019년도의 프로젝트에서도 성공 방정식을 적용하듯이 기존 스택들을 끌어오기 시작한 것이죠.
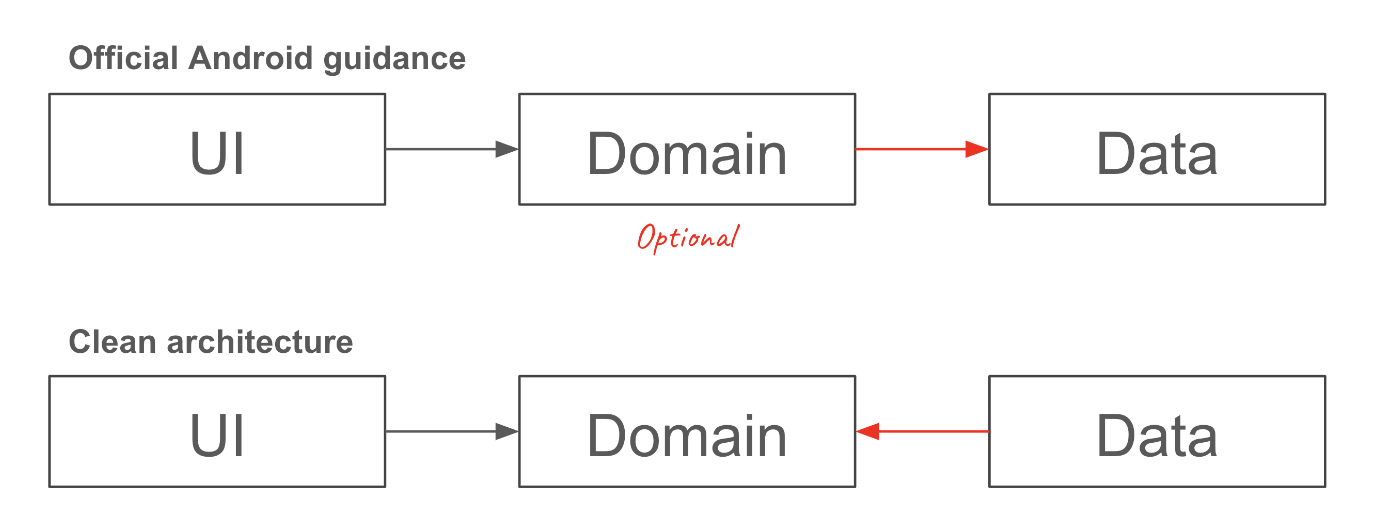
| 중요한 것은 마이크로서비스 아키텍처가 아니다
사실 마이크로서비스 아키텍처는 그렇게 중요하지 않습니다. 정확히 말하면 저 타이틀 자체는 아무것도 아니라는 것이죠. 진짜 중요한 것은 마이크로서비스 아키텍처가 왜 시스템을 여러 작은 서비스로 분할하려고 하는지에 대한 배경과 목적입니다. 지난 10년간 너무나 많은 프로젝트들이 마이크로서비스 아키텍처라는 타이틀에 집착하여 나누지 않아도 될 시스템을 나누게 되었고, 그 결과 모놀리식 시스템이 더 적합한 프로젝트들이 마이크로 서비스로 분활되어 부작용만 뿜어내는 구조를 가지게 되었습니다. ‘이 시스템은 몇 개의 서비스로 분할되는 것이 맞는가?’와 같은 구조적인 해석을 요구하는 질문에 딱 맞아떨어지는 정답이 없다보니 마이크로서비스 아키텍처에 대한 각각의 해석이 난무하게 되었고, 이 해석이 각자의 성공 경험으로 치환되면서 세상에 수많은 ‘우리식 마이크로서비스 아키텍처’가 생겨나게 되었습니다.
마이크로서비스 아키텍처가 본격적으로 확산되기 시작한지 10년이 되었고, 그 시기에 만들어진 시스템들이 이제 레거시 시스템이 되어가는 이 시점에서 마이크로서비스 아키텍처가 왜 등장하게 되었고 그 이전에는 어떤 문제들이 있었는지, 혹시 마이크로서비스 아키텍처가 당연하게 쓰이는 지금에는 그 문제들이 다 해결되었는지 생각해보는 것은 목표 지향적으로 달려온 소프트웨어 개발 현장에 적절한 브레이크가 될 수 있을 것이라고 생각합니다. 조금 역설적으로 들릴 수 있지만, 마이크로서비스 아키텍처에 대한 이해가 깊어지면 오히려 마이크로서비스 아키텍처를 사용하지 않는 선택을 할 수도 있을 것이고, 반대로 마이크로서비스 아키텍처를 정말 필요한 곳에 적절하게 적용할 수도 있을 것입니다.
대부분의 마이크로서비스 아키텍처 (MSA) 강의나 도서에서는 원론적인 이야기만 하고, 이 마이크로서비스 아키텍처가 가진 실질적인 문제점들을 숨깁니다.
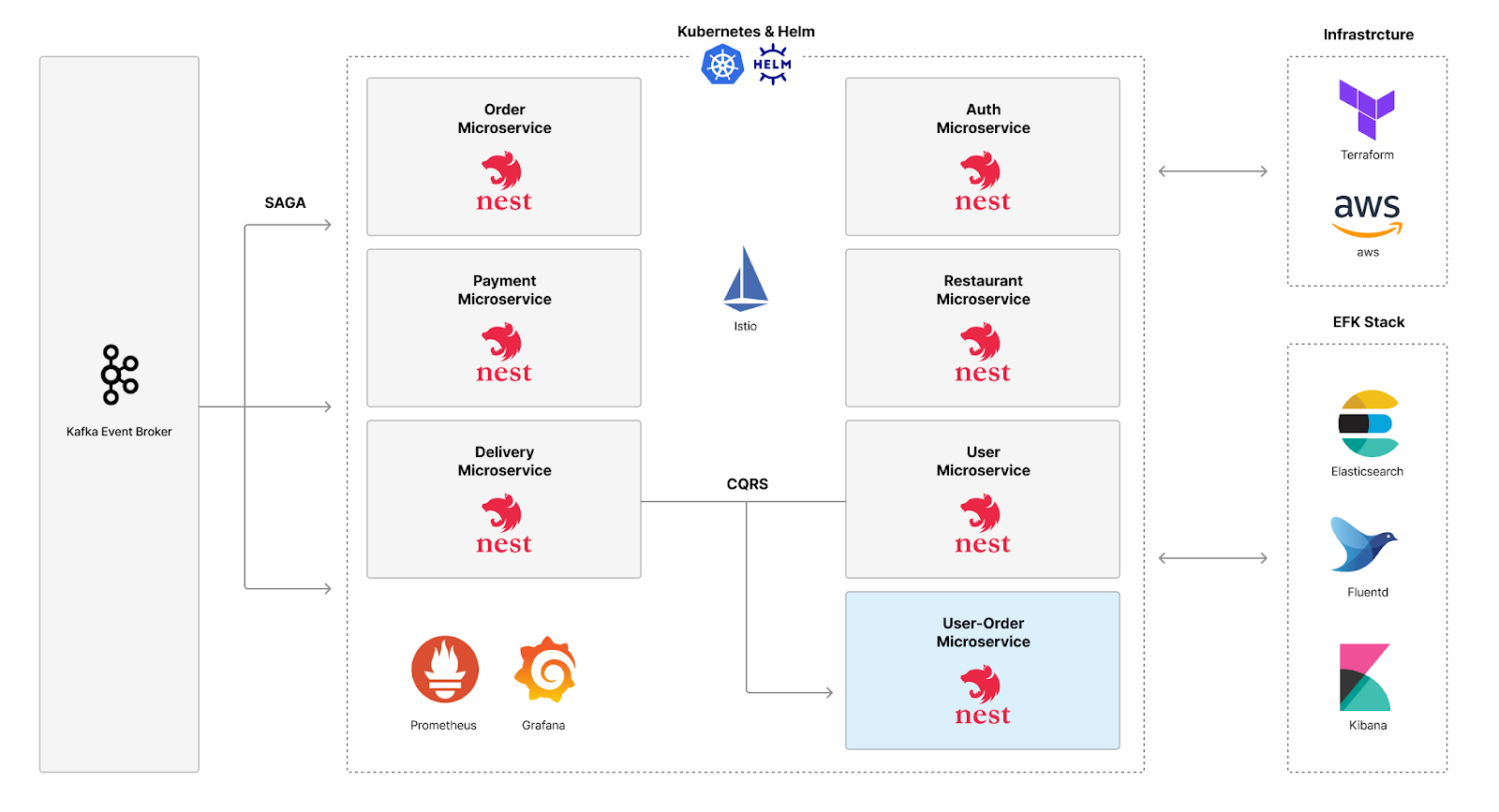
하지만, 패스트캠퍼스에서 출시한 [MSA 워크샵 : 12가지 핵심 기술로 구현하는 MSA 실무 프로젝트] 강의에서는 MSA 실무자들을 위해 MSA 구현시 발생하는 문제 상황들과 주의해야 할 기술들까지 단점부터 장점까지! 전부 알려줍니다.
개발자들이 가장 어려워하는 비동기 호출, 트랙잭션 처리, CQRS 패턴을 포함한 12가지 MSA 핵심기술은 물론, SNS 프로젝트로 실무에서 마주치는 다양한 실패 케이스까지 함께 해결해볼 수 있다고 하는데요.

현장에서 발생하는 실무 이슈들을 담은 Q&A집까지 무료로 제공한다고 합니다!
대기업 리드급 현직 개발자에게 배우는 실무 중심의 MSA, 지금 바로 만나보세요 >>















































































![[2024 네카라쿠배 코딩테스트 합격을 위한 3가지 전략 | 단기 합격 꿀팁!]](https://fcaiing.co.kr/wp-content/uploads/2024/04/이미지1.jpg)







